

목록Machine Learning/머신러닝 (45)
Allen's 데이터 맛집
지도학습, 비지도학습, 준지도학습, 그리고 강화학습은 기계 학습의 주요 패러다임을 나타냅니다. 각각의 학습 방법에는 특정한 특징과 목적이 있습니다. 1. 지도학습 (Supervised Learning) 지도학습은 입력 데이터와 그에 상응하는 정답(레이블)을 사용하여 모델을 훈련시키는 방법입니다. 모델은 입력과 정답의 관계를 학습하고, 새로운 입력이 주어졌을 때 해당 정답을 예측할 수 있습니다. 지도학습은 분류(Classification)와 회귀(Regression) 문제에 주로 사용됩니다. 예시: 이미지 분류, 스팸 메일 감지, 주택 가격 예측 등 2. 비지도학습 (Unsupervised Learning) 비지도학습은 정답(레이블)이 주어지지 않은 데이터에서 패턴이나 구조를 찾는 방법입니다. 모델은 데이..
제가 예전에 머신러닝에 대해서 공부를 하다가 흥미로운 아이디어를 제출하고, 함께 공유할 수 있는 사이트를 공유하겠습니다. 지도학습 분류사례 분류사례 제출 https://docs.google.com/forms/d/e/1FAIpQLSfDN7JtYYpAAw8SxEh0l1jKGRbGiZy0i-H2V7vKCFnHx7KR9g/viewform' 머신러닝 1 - 지도학습 / 분류의 사례 머신러닝/지도학습/분류의 좋은 사례가 있으면 알려주세요. 이곳에는 어느정도 검증이 된 정보가 등록 되었으면 좋겠습니다. docs.google.com 분류사례 아이디어 공유 https://docs.google.com/spreadsheets/d/1uPbxjqGmpgdNE14N_cFJs7CcPgOv60dbdkVEHldQpEw/edit#gid..
 [머신러닝] 분류 : XGBoost
[머신러닝] 분류 : XGBoost
"뛰어난 예측의 힘, XGBoost 분류 모델" 이번에는 머신러닝 분야에서 현재 굉장히 인기 있는 'XGBoost' 분류 모델에 대해 알아보겠습니다. XGBoost는 예측 성능을 극대화하고 과적합을 줄이는 데에 뛰어난 성능을 보이는 알고리즘입니다. XGBoost는 Gradient Boosting 알고리즘을 기반으로 한 앙상블 모델로, 여러 개의 결정 트리를 조합하여 예측을 수행합니다. 트리를 순차적으로 생성하면서, 이전 트리의 예측 오차를 보완하는 방식으로 학습됩니다. 이미지출처:https://m.blog.naver.com/winddori2002/221931868686?view=img_1 간단한 파이썬 코드 예제: from sklearn.datasets import load_iris from xgboos..
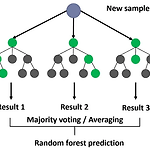 [머신러닝] 분류 : 랜덤 포레스트(Random Forest)
[머신러닝] 분류 : 랜덤 포레스트(Random Forest)
"데이터의 숲, Random Forest 분류 모델" 이번에는 머신러닝에서 널리 사용되는 'Random Forest(랜덤 포레스트)' 분류 모델에 대해 알아보겠습니다. 이 모델은 여러 개의 의사 결정 트리를 결합하여 예측하는 강력하고 안정적인 알고리즘입니다. Random Forest 분류 모델은 여러 개의 의사 결정 트리를 생성하고, 각 트리의 예측 결과를 투표하여 최종 결과를 결정하는 방식으로 작동합니다. 이로 인해 각 트리의 장점을 살리고, 과적합을 방지하며 예측의 정확도를 높일 수 있습니다. 이미지출처:https://medium.com/@roiyeho/random-forests-98892261dc49 간단한 파이썬 코드 예제: from sklearn.datasets import load_iris f..