

목록전체 글 (367)
Allen's 데이터 맛집
 [머신러닝] 분류 : 고객 구매 데이터로 물품 제시간 도착여부 예측하기.
[머신러닝] 분류 : 고객 구매 데이터로 물품 제시간 도착여부 예측하기.
이번 포스팅에선 Kaggle의 'E-Commerce Shipping Data'의 고객 구매 데이터를 사용해서 고객이 주문한 물품이 제시간에 도착하였는지 여부(Reached.on.Time_Y.N)를 예측해 보겠습니다. About Dataset Context An international e-commerce company based wants to discover key insights from their customer database. They want to use some of the most advanced machine learning techniques to study their customers. The company sells electronic products. Content The data..
 [머신러닝] 분류 : 백화점 고객 데이터로 고객의 성별 예측하기
[머신러닝] 분류 : 백화점 고객 데이터로 고객의 성별 예측하기
이번 포스팅에서는 빅데이터 분석기사의 실제 분류 문제를 가지고 데이터 분석 및 예측을 진행해 보겠습니다. 문제 고객 3,500명에 대한 학습용 데이터(y_train.csv, X_train.csv)를 이용하여 성별예측 모형을 만든 후, 이를 평가용 데이터(X_test.csv)에 적용하여 얻은 2,482명 고객의 성별 예측값(남자일 확률)을 다음과 같은 형식의 csv 파일로 생성하시오. (제출한 모델의 성능은 ROC-AUC 평가지표에 따라 채점) 데이터 가져오기 데이터를 받아오고 각종 세팅을 한 다음 X, Y, X_submission 변수에 각 train, test csv 데이터들을 담습니다. 데이터 전처리 X데이터를 결합하고 info()를 통해 데이터 타입을 확인하고, 추가로 결측치까지 확인합니다. '환불..
 [머신러닝] 분류 : XGBoost
[머신러닝] 분류 : XGBoost
"뛰어난 예측의 힘, XGBoost 분류 모델" 이번에는 머신러닝 분야에서 현재 굉장히 인기 있는 'XGBoost' 분류 모델에 대해 알아보겠습니다. XGBoost는 예측 성능을 극대화하고 과적합을 줄이는 데에 뛰어난 성능을 보이는 알고리즘입니다. XGBoost는 Gradient Boosting 알고리즘을 기반으로 한 앙상블 모델로, 여러 개의 결정 트리를 조합하여 예측을 수행합니다. 트리를 순차적으로 생성하면서, 이전 트리의 예측 오차를 보완하는 방식으로 학습됩니다. 이미지출처:https://m.blog.naver.com/winddori2002/221931868686?view=img_1 간단한 파이썬 코드 예제: from sklearn.datasets import load_iris from xgboos..
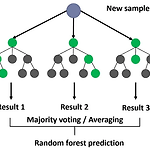 [머신러닝] 분류 : 랜덤 포레스트(Random Forest)
[머신러닝] 분류 : 랜덤 포레스트(Random Forest)
"데이터의 숲, Random Forest 분류 모델" 이번에는 머신러닝에서 널리 사용되는 'Random Forest(랜덤 포레스트)' 분류 모델에 대해 알아보겠습니다. 이 모델은 여러 개의 의사 결정 트리를 결합하여 예측하는 강력하고 안정적인 알고리즘입니다. Random Forest 분류 모델은 여러 개의 의사 결정 트리를 생성하고, 각 트리의 예측 결과를 투표하여 최종 결과를 결정하는 방식으로 작동합니다. 이로 인해 각 트리의 장점을 살리고, 과적합을 방지하며 예측의 정확도를 높일 수 있습니다. 이미지출처:https://medium.com/@roiyeho/random-forests-98892261dc49 간단한 파이썬 코드 예제: from sklearn.datasets import load_iris f..