

Allen's 데이터 맛집
[머신러닝] 회귀 : 대학원 입학 예측 본문
대학원 입학 예측(회귀)
데이터를 가지고 대학원에 입학할 확률을 구해보겠습니다.
- 예측할 값(target): "Chance of Admit "
- 평가: r2
- data(3개): t2-2-X_train, t2-2-y_train, t2-2-X_test
- 제출 형식(Serial No.-> id, 예측 값 -> target)
id, target
28,0.741696
76,0.779616
151,0.897247
데이터 불러오기
각각 데이터를 불러옵니다.
import pandas as pd
# 데이터 불러오기
X_train = pd.read_csv("../input/big-data-analytics-certification/t2-2-X_train.csv")
y_train = pd.read_csv("../input/big-data-analytics-certification/t2-2-y_train.csv")
X_test = pd.read_csv("../input/big-data-analytics-certification/t2-2-X_test.csv")EDA
요약 데이터, 타입, 결측치와 기초통계를 통해 데이터를 파악합니다.
# 데이터 확인
X_train.head(3)
X_test.head(3)
y_train.head(3)
# 타입 확인
X_train.info()
# 결측치 확인
print(X_train.isnull().sum())
print(X_test.isnull().sum())
# 기초 통계
X_train.describe()


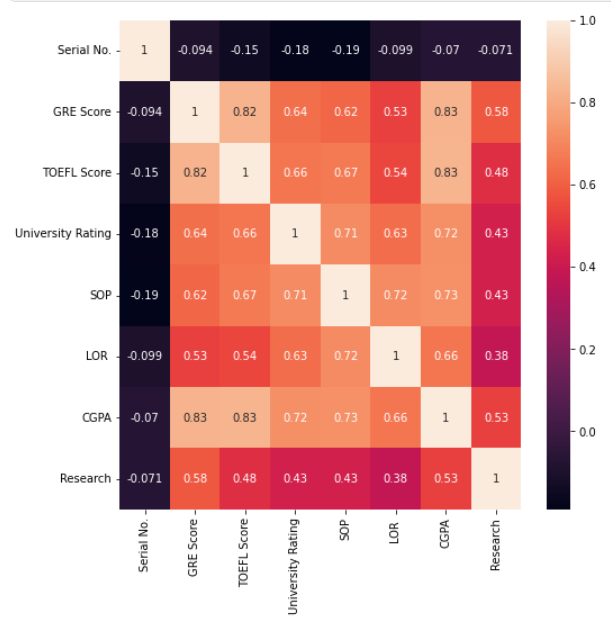
타겟 데이터의 분포도를 위해 막대그래프, 그리고 상관관계를 시각화로 파악하기 위해 히트맵을 그려봅니다.
그리고 X_train, y_train과 병합하여 데이터를 비교해 보고 corr()을 사용하여 'Chance of Admit' 열과 다른 모든 열간의 상관관계를 출력해 봅니다.
# 타겟 확인
y_train["Chance of Admit "].hist()
# 상관관계
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(8, 8))
sns.heatmap(X_train.corr(), annot=True)
plt.show()
train = X_train.join(y_train.set_index("Serial No."), on="Serial No.")
train.head(3)
train[train.columns[1:]].corr()["Chance of Admit "].sort_values(ascending=False)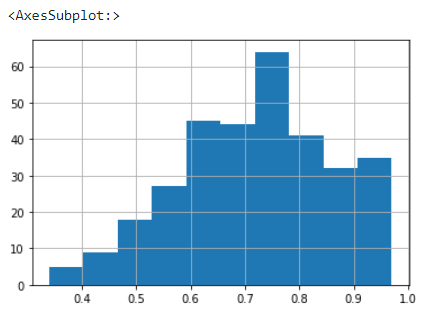


모델 학습 및 평가
LinearRegression, RandomForestRegressor, LinearRegression 회귀 모델들을 사용하여 각각 r2 score를 출력합니다.
# 선형회귀 모델
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
from sklearn.model_selection import cross_val_score
scores = cross_val_score(lr, X_train.iloc[:,1:] , y_train["Chance of Admit "] , scoring='r2', cv=5)
print(scores)
print(scores.mean())
#0.7793443258102183>>> [0.68755618 0.77275276 0.78523589 0.80534171 0.84583509]
0.7793443258102183
# 랜덤포레스트
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(random_state=2022)
scores = cross_val_score(rf, X_train.iloc[:,1:] , y_train["Chance of Admit "] , scoring='r2', cv=5)
print(scores)
print(scores.mean())
# 0.735532640585703>>> [0.64869265 0.73684678 0.74006195 0.77770429 0.77435753]
0.735532640585703
# 선형회귀 모델
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train.iloc[:,1:], y_train["Chance of Admit "])
pred = model.predict(X_test.iloc[:,1:])
pred>>> array([0.74169551, 0.77961555, 0.89724685, 0.62178957, 0.52329688,
0.79905929, 0.5533676 , 0.53842986, 0.53349439, 0.81605173,
0.6184423 , 0.86062093, 0.44377896, 0.65915476, 0.44378392,
0.77344472, 0.91707277, 0.94723587, 0.99500994, 0.62889498,
0.73713179, 0.71177513, 0.77303894, 0.83329803, 0.69294529,
0.63183488, 0.90280343, 0.64011081, 0.97622107, 0.66122198,
0.75819948, 0.52358472, 0.66289347, 0.78847735, 0.68487084,
0.96045066, 0.59755096, 0.64267599, 0.93231842, 0.70104901,
0.65487186, 0.79000375, 0.69886094, 0.67133938, 0.83247237,
0.76054207, 0.50555231, 0.7312788 , 0.85142943, 0.84877528,
0.53721188, 0.85891425, 0.94861598, 0.72704391, 0.77370375,
0.63392911, 0.58372317, 0.59631484, 0.80653472, 0.8850056 ,
0.83377169, 0.65649764, 0.69555057, 0.70981663, 0.60819004,
0.68285873, 0.6771213 , 0.92522669, 0.67304201, 0.8797406 ,
0.6558163 , 0.68267974, 0.78149038, 0.92229331, 0.88397378,
0.70807094, 0.90657563, 0.93510992, 0.85559716, 0.75021205])
예측 결과 제출 양식에 맞게 id와 target으로 이뤄진 데이터프레임을 만듭니다.
pd.DataFrame({'id': X_test['Serial No.'], 'target': pred}).to_csv('003000000.csv', index=False)
pd.read_csv("003000000.csv")



