

Allen's 데이터 맛집
[머신러닝] 분류 : 성인 인구조사 소득 예측 본문
성인의 소득을 아래의 다양한 칼럼들을 사용하여 예측을 진행해 보겠습니다.
- age: 나이
- workclass: 고용 형태
- fnlwgt: 사람의 대표성을 나타내는 가중치(final weight)
- education: 교육 수준
- education.num: 교육 수준 수치
- marital.status: 결혼 상태
- occupation: 업종
- relationship: 가족 관계
- race: 인종
- sex: 성별
- capital.gain: 양도 소득
- capital.loss: 양도 손실
- hours.per.week: 주당 근무 시간
- native.country: 국적
- income: 수익 (예측해야 하는 값)
데이터 불러오기
데이터 분석을 위해 adult.csv 파일을 불러오고 X_train, X_test, y_train, y_test 변수를 사용하여 각각 데이터를 담아줍니다.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
def exam_data_load(df, target, id_name="", null_name=""):
if id_name == "":
df = df.reset_index().rename(columns={"index": "id"})
id_name = 'id'
else:
id_name = id_name
if null_name != "":
df[df == null_name] = np.nan
X_train, X_test = train_test_split(df, test_size=0.2, random_state=2021)
y_train = X_train[[id_name, target]]
X_train = X_train.drop(columns=[target])
y_test = X_test[[id_name, target]]
X_test = X_test.drop(columns=[target])
return X_train, X_test, y_train, y_test
df = pd.read_csv("../input/adult-census-income/adult.csv")
X_train, X_test, y_train, y_test = exam_data_load(df, target='income', null_name='?')
X_train.shape, X_test.shape, y_train.shape, y_test.shape>>> ((26048, 15), (6513, 15), (26048, 2), (6513, 2))
EDA
shape, head, info등의 함수를 사용하여 데이터를 파악합니다.
# 데이터 크기 확인
X_train.shape, X_test.shape, y_train.shape
# 데이터 확인
X_train.head()
# 타겟 수 확인
y_train['income'].value_counts()
# type확인
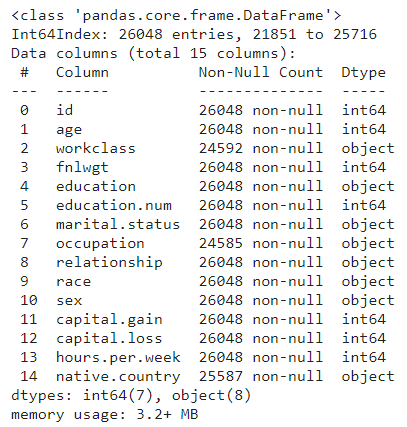
X_train.info()>>> ((26048, 15), (6513, 15), (26048, 2))


데이터 전처리
데이터 편의를 위해 변수명을 바꾸고, 추후 제출할 때 사용할 id를 Y_id변수에 담아줍니다.
income 변수를 cat.codes 함수를 사용하여 뉴메릭 타입으로 변경해 줍니다.
dfX변수에 전처리를 위해 X데이터를 합쳐주고 Y_id변수에 id값은 담아주었기 때문에 필요 없는 id칼럼은 제거해 줍니다.
X = X_train
X_submission = X_test
Y = y_train
Y_id = Y['id']
Y_id
Y['income'] = Y['income'].astype('category').cat.codes
Y = Y['income']
Y
dfX = pd.concat([X, X_submission])
# capital.gain capital.loss 이상치 제거 필요
dfX = dfX.drop(columns = 'id')

capital.loss와 captial.gain의 유일값을 출력하고 결측치인 0 값을 평균값으로 대체를 해줍니다.
get_dummies 함수를 통해 원핫인코딩으로 카테고리형 타입의 칼럼들을 뉴메릭 타입으로 변경해 줍니다.
그리고 카테고리형 타입 속성들을 제거해 준 후 전처리가 끝난 데이터들은 다시 X데이터와 제출용 X데이터로 나눕니다.
df['capital.loss'].unique()
df['capital.gain'].unique()
df.loc[df['capital.loss'] == 0] = df['capital.loss'].mean()
df.loc[df['capital.gain'] == 0] = df['capital.loss'].mean()
feature = ['workclass','education','marital.status','occupation','relationship','race','sex','native.country']
temp = pd.get_dummies(dfX[feature])
dfX = pd.concat([dfX,temp], axis = 1)
dfX = dfX.drop(columns = dfX.select_dtypes(include = 'O'))
size = X.shape[0]
X_use = dfX.iloc[:size, :]
X_submission_use = dfX.iloc[size :, :]

학습 모델 선택 및 평가
가장 accuracy점수가 좋았던 DecisionTreeClassifier 모델을 선택하여 제출용 데이터프레임을 만듭니다.
그리고 잘 만들어졌는지 확인합니다.
model = DecisionTreeClassifier(max_depth = 13, random_state = 7438).fit(xtrain, ytrain)
pred = model.predict(X_submission_use)
#DT 13 0.8948 0.8467 0.0481 0.7796
Y_id = Y_id.iloc[:6513]
submission = pd.DataFrame({'id' : Y_id, 'income' : pred})
submission.to_csv('result.csv', index = False)
df = pd.read_csv('result.csv')
df
y_test = (y_test['income'] != '<=50K').astype(int)
from sklearn.metrics import accuracy_score
print('accuracy score:', (accuracy_score(y_test, pred)))
y_test>>> accuracy score: 0.8518347919545525

https://www.kaggle.com/datasets/uciml/adult-census-income
Adult Census Income
Predict whether income exceeds $50K/yr based on census data
www.kaggle.com



