

Allen's 데이터 맛집
[3] ETF목록 데이터 분석과 시각화 본문
네이버금융에서 ETF 목록 데이터를 수집하고 해당 데이터를 전처리해서 분석을 하고 시각화를 해봅시다!
ETF 데이터 수집
수집, 분석 그리고 시각화를 할 라이브러리를 받아오고 requests 라이브러리로 네이버금융 url을 사용하여 찾고자 하는 목록 result와 etfitemlist을 받아와서 저희가 데이터를 EDA를 할 수 있게 키-값 형태의 데이터 프레임 형식으로 만듭니다
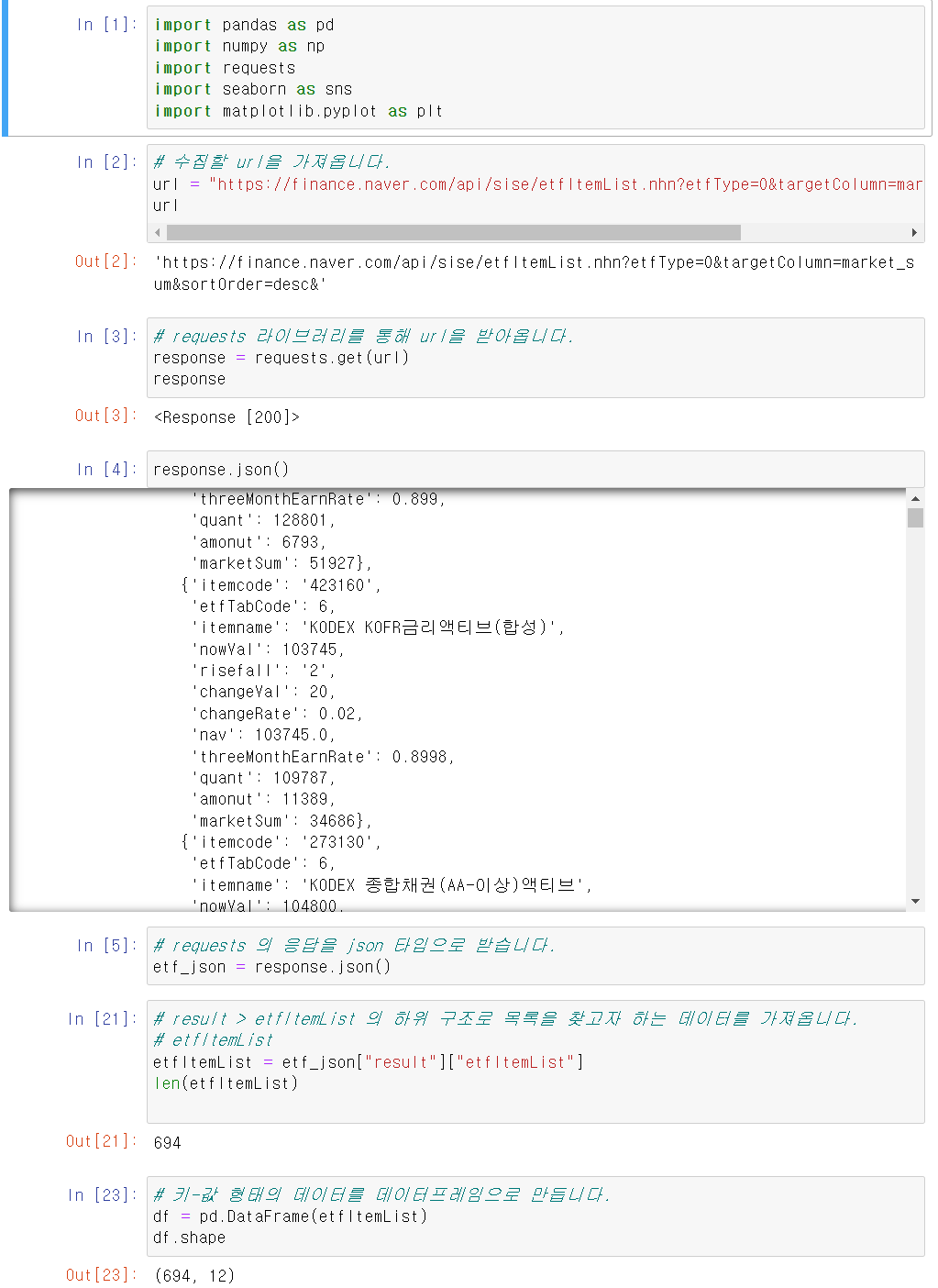

info() 함수를 사용하여 데이터들의 정보를 확인해 봅니다.
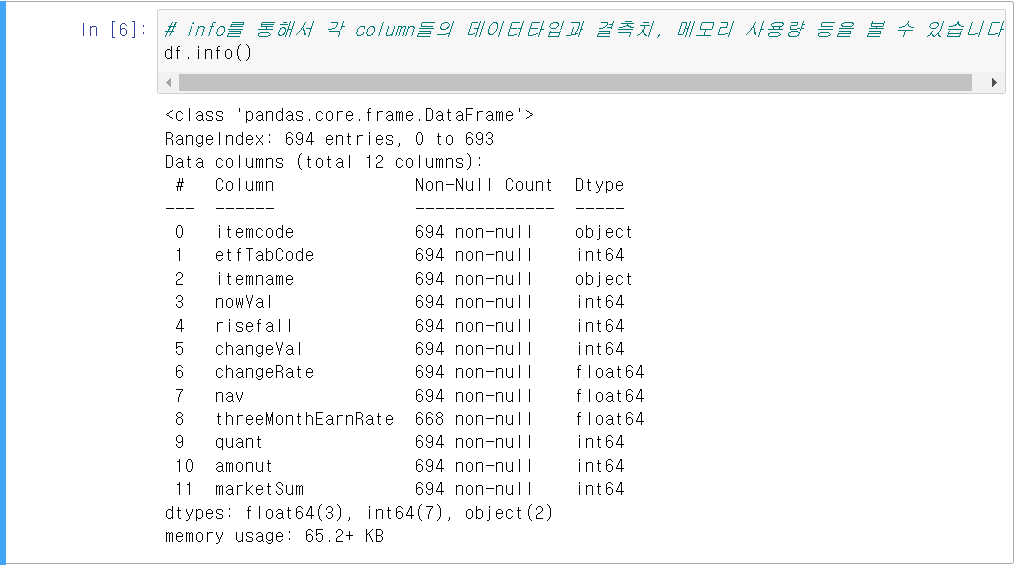
etfTabCode는 해당 사이트에서 전체(0), 국내 시장지수(1), 국내 업종/테마(2), 국내 파생(3) ~
해외 주식(4), 원자재(5), 채권(6), 기타(7)로 자료가 구분되어 있습니다.
저희는 앞으로 국내 시장지수를 가지고 분석 및 시각화를 할 것이기 때문에 1번 index를 사용하겠습니다.
데이터 전처리
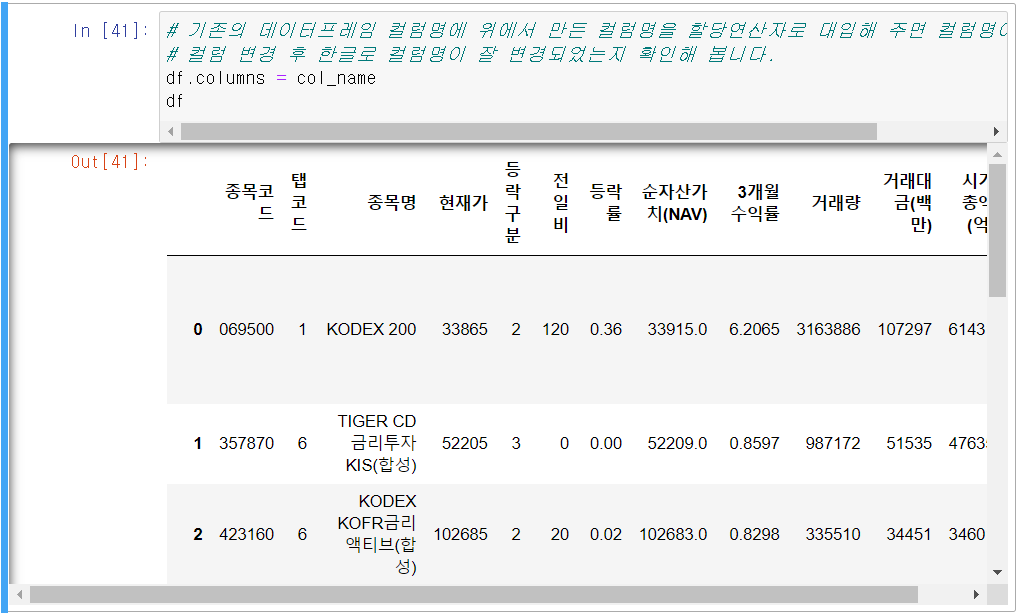
ETF데이터프레임에 새로운 열(etfTabName)을 추가하여 ETF 코드(etfTabCode)에 따라 해당 ETF의 유형을 한글로 표시합니다.
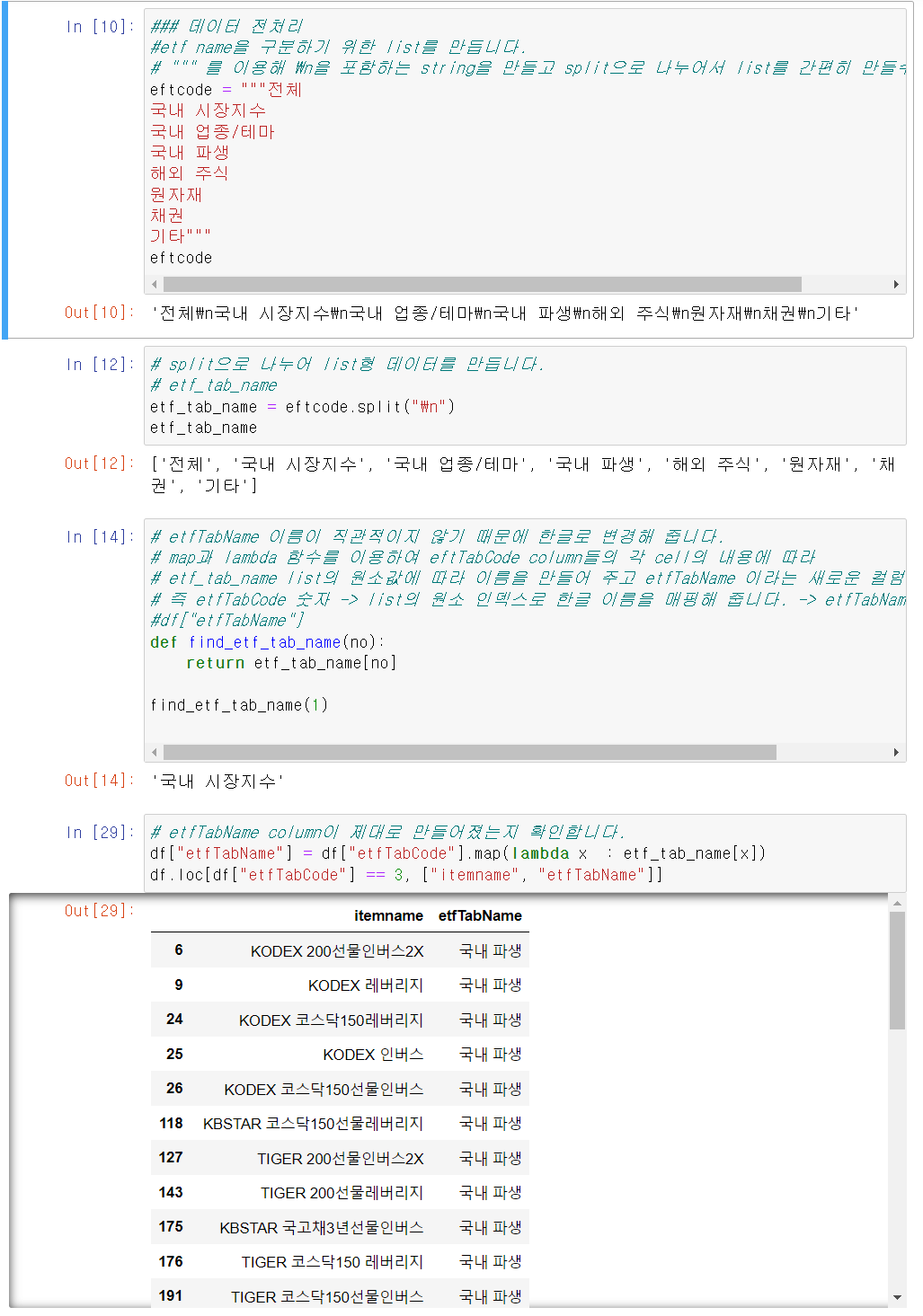
직관적으로 이해하기 쉽게 영문 칼럼들을 임의로 적은 한글로 변경을 합니다.
df.columns(기존 칼럼)에 위에 미리 만들어 놓은 col_name을 대입합니다.
무조건 각각 컬럼의 순서가 맞아야 하니 주의하시기 바랍니다
파생변수 생성하기
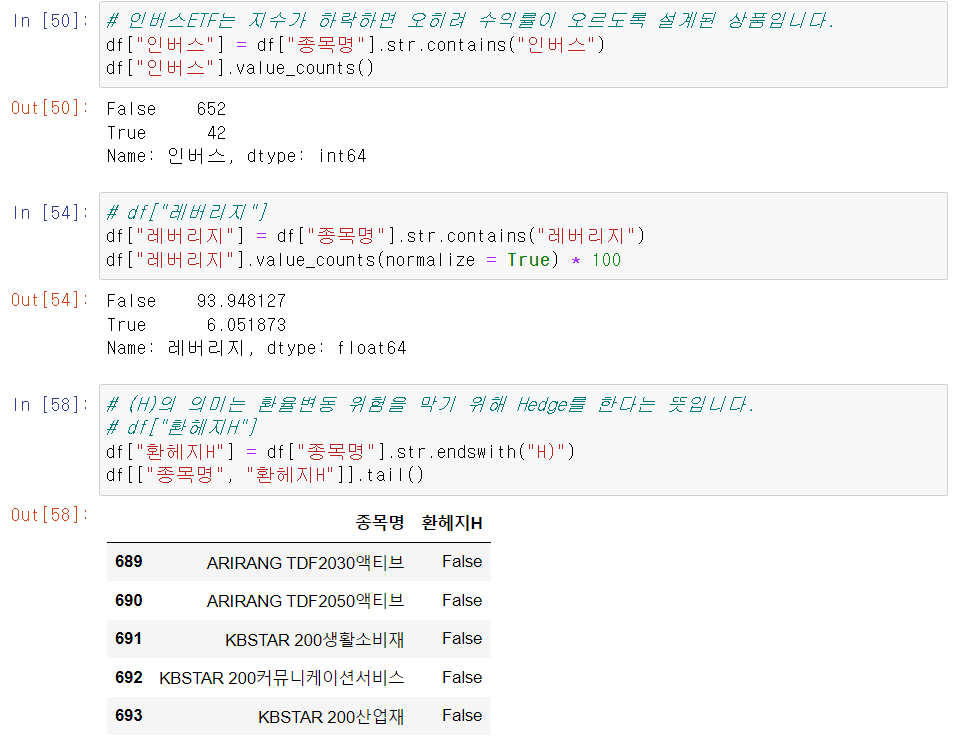
종목명에 각각 인버스(invers), 레버리지(leverage), 헤지(hedge)가 들어가면 True가 되므로, 해당값을 따로 빼서 새로운 파생변수(칼럼)를 생성합니다.
파생변수 생성 후 각각의 수와, 비율과 데이터를 직접 확인해 봅니다
시각화
시각화를 하기 이전에 한글과 폰트, 마이너스폰트와 그래프 설정을 합니다.
# 시각화 폰트 설정
def get_font_family():
"""
시스템 환경에 따른 기본 폰트명을 반환하는 함수
"""
import platform
system_name = platform.system()
# colab 사용자는 system_name이 'Linux'로 확인
if system_name == "Darwin" :
font_family = "AppleGothic"
elif system_name == "Windows":
font_family = "Malgun Gothic"
else:
!apt-get install fonts-nanum -qq > /dev/null
!fc-cache -fv
import matplotlib as mpl
mpl.font_manager._rebuild()
findfont = mpl.font_manager.fontManager.findfont
mpl.font_manager.findfont = findfont
mpl.backends.backend_agg.findfont = findfont
font_family = "NanumBarunGothic"
return font_family
# 그래프 스타일 설정
# plt.style.use("fivethirtyeight")
# plt.style.use("bmh")
# dark mode 사용자를 위한 스타일 추천
plt.style.use("seaborn-whitegrid")
# 폰트설정
plt.rc("font", family = font_family)
# 마이너스폰트 설정
plt.rc("axes", unicode_minus=False)
# 그래프에 retina display 적용
from IPython.display import set_matplotlib_formats
set_matplotlib_formats("retina")
아래 이미지처럼 한글과 -가 잘 표시되면 됩니다.
isna() 함수를 통해서 결측치를 확인할 수 있지만 아래처럼 heatmap을 사용하면 결측치에 대해서 한눈에 파악하기 용이합니다.
3개월 수익률에 대해서만 결측치가 있음을 확인할 수 있습니다.

seaborn의 countplot을 사용하여 각 주식 유형의 빈도수를 파악할 수 있고
예상과 같이 국내업종 테마가 제일 많은 것을 알 수 있습니다.
value_counts()의 normalize=True 옵션을 통해 백분율로도 표기가 가능합니다.
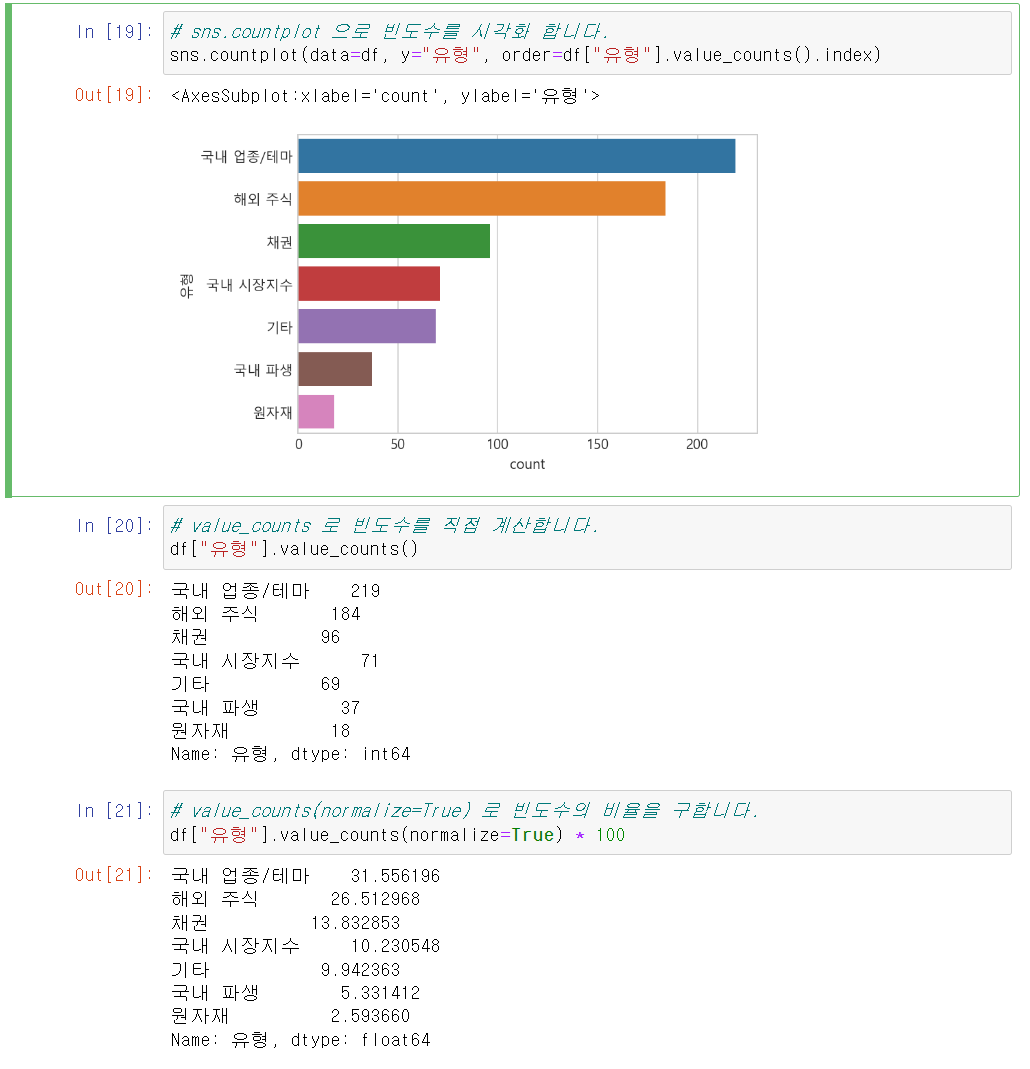
유형 칼럼의 빈도수를 봅니다
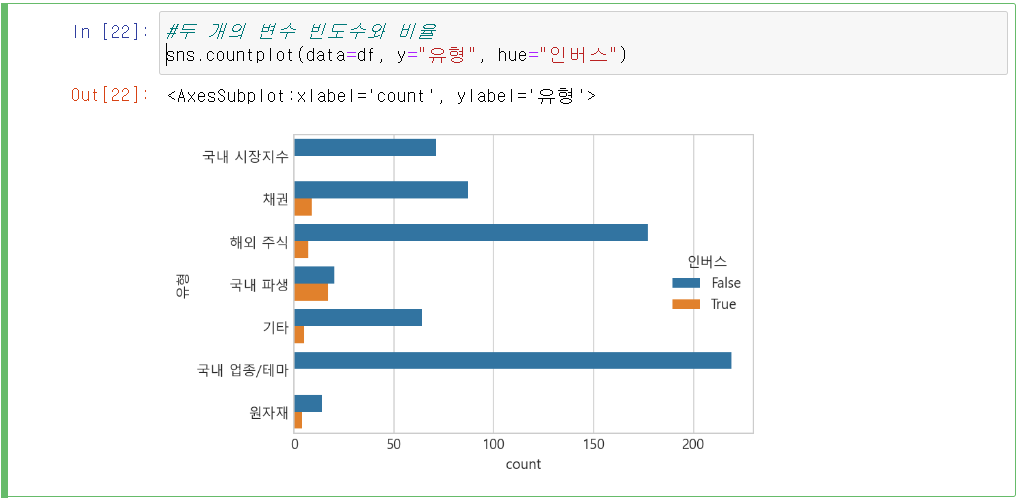
seaborn countplot의 hue 옵션을 사용하여 인버스여부를 다른 색상으로 표시해 봅니다. 해당 그래프로 인버스 외에 레버리지, 헤지스 빈도수도 같이 보기가 가능합니다.
국내 파생기업, 채권, 해외주식정도에 인버스가 있는 것을 확인할 수 있습니다.
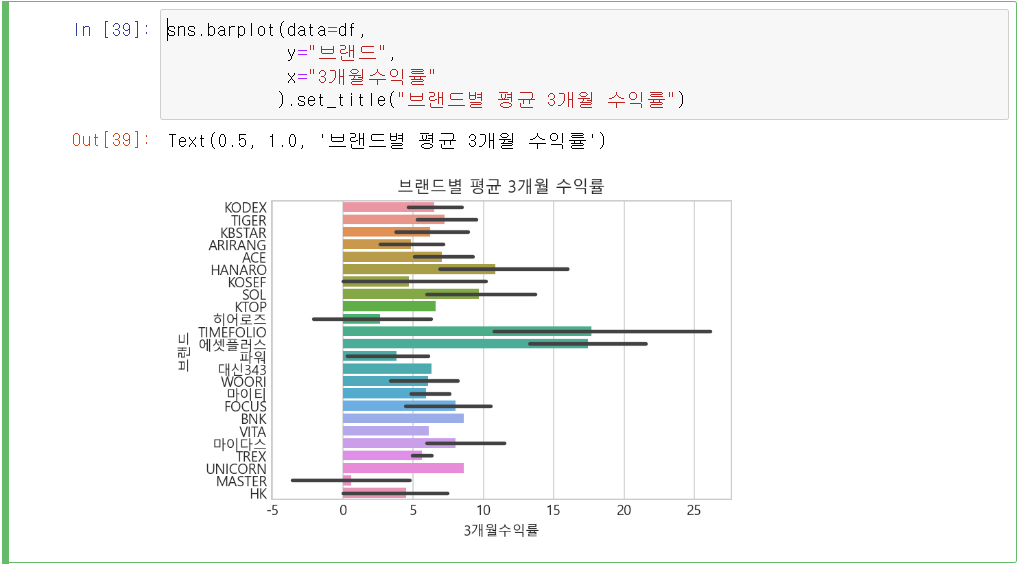
seaborn의 bar chart를 이용하여 각 브랜드에 대한 3개월 수익률의 평균값을 볼 수 있습니다. 검은색 막대는 저희가 통계공부를 할 때 공부했던 신뢰구간으로써 ci로 설정을 할 수 있습니다.
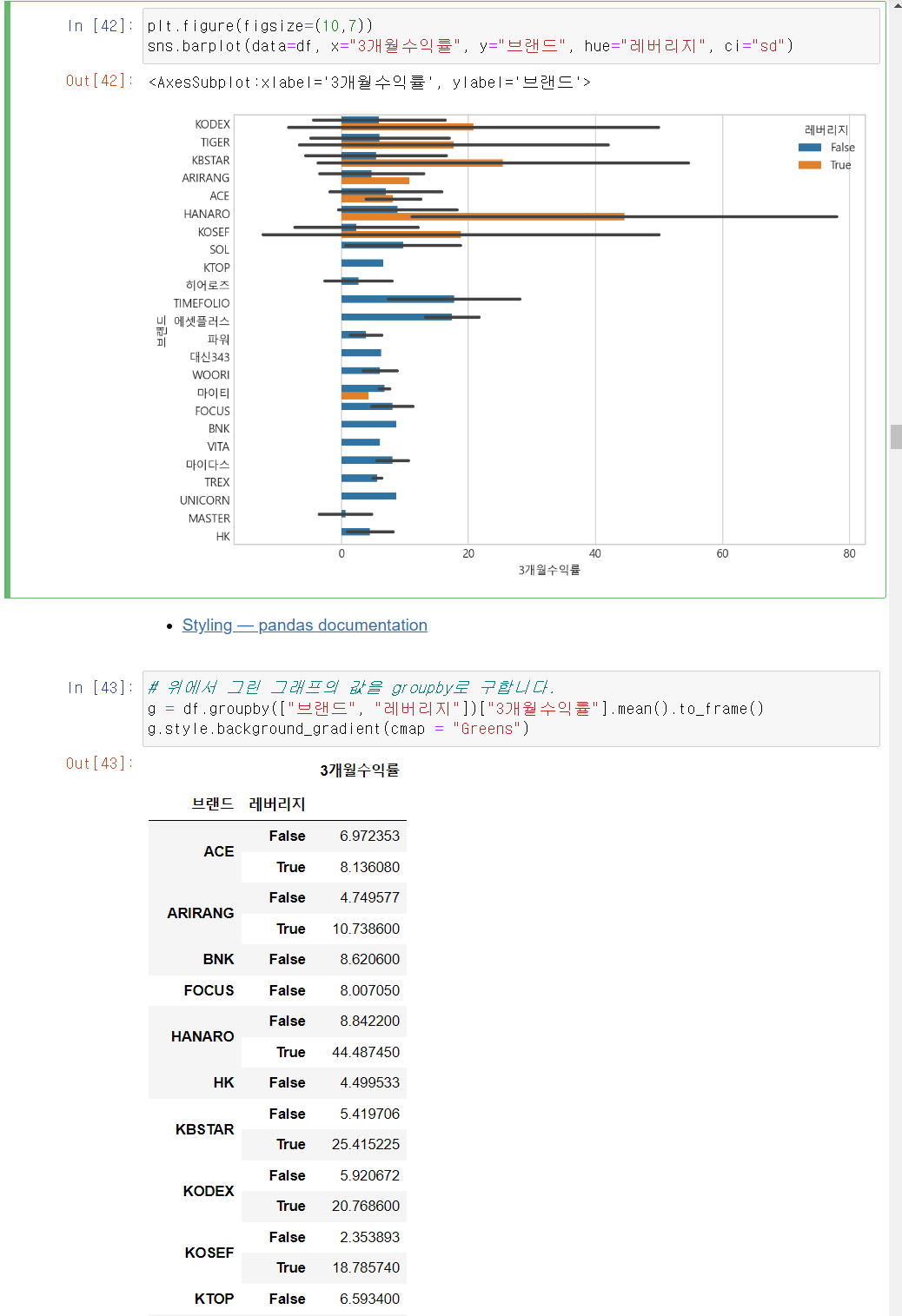
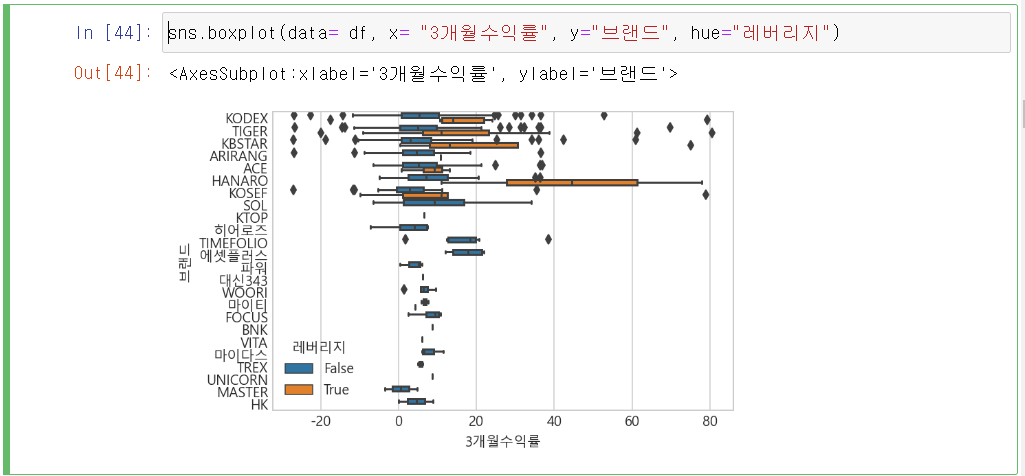
브랜드 대비 3개월 수익률에 대한 정보를 레버리지 값의 차이를 barplot으로 봅니다.
레버리지 유/무에 따라서 평균 3개월 수익률은 많은 차이가 없지만, 표준편차의 경우 레버리지가 있을 경우 굉장히 편차(ci="sd")가 심함을 확인할 수 있습니다.
boxflot을 사용하면 추가적으로 이상치까지 한눈에 파악할 수 있습니다.
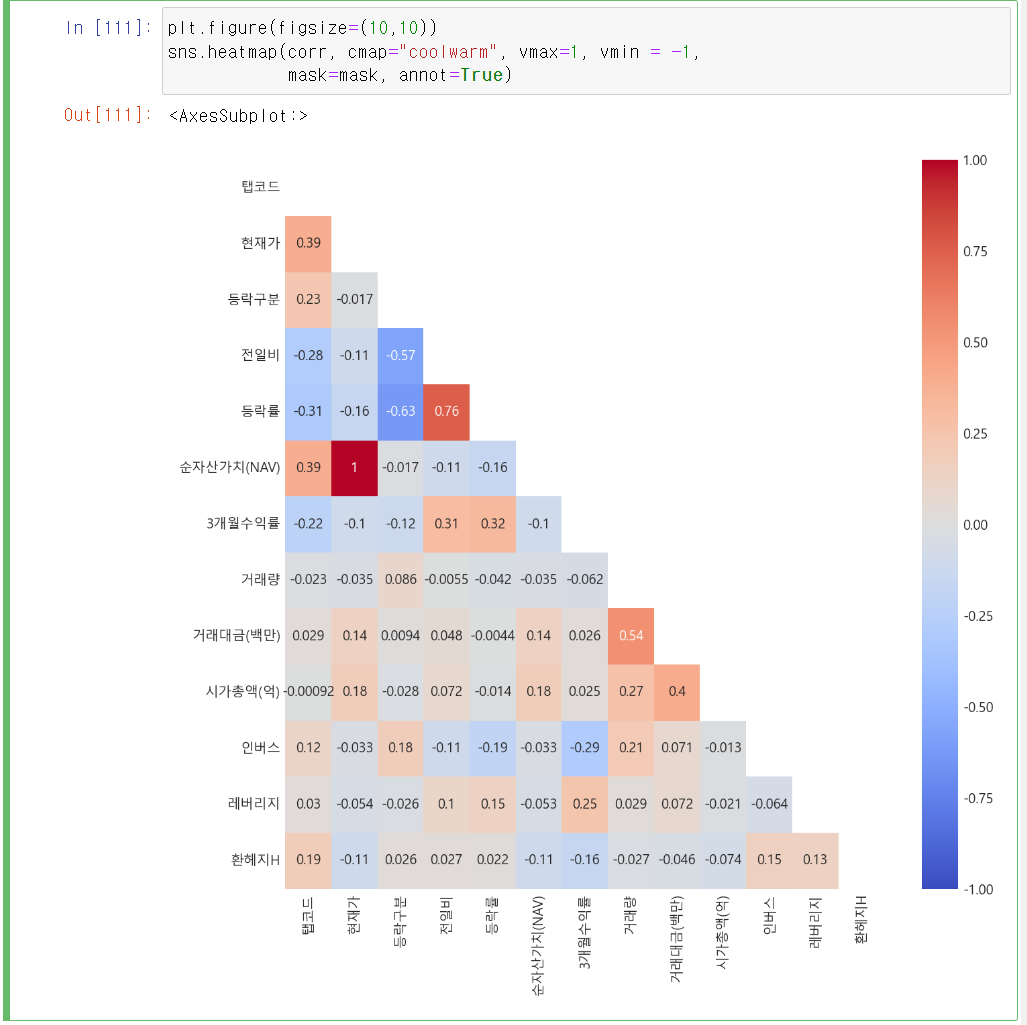
마지막으로 seaborn의 heatmap으로 상관계수를 시각화해 봅니다. 코드로(corr()) 상관관계를 찍어보는 것보단 색으로 나타내어 한눈에 파악하기가 용이합니다.
이번 포스팅은 네이버금융 사이트에서 데이터를 수집해 와서 분석하기 용이한 형태로 전처리를 해보고 분석을 해서 최종적으로 시각화를 해 보았습니다. 시각화에 중점을 두고 상황에 따라 다른 여러 가지 시각화 도구들을 사용해 보았습니다.
수치로 출력하는 것보다 확실히 시각화로 나타내는 것이 가독성이 훨씬 좋았고 금융/주식에 전문가가 아닌 저도 어느 정도 주식 시장과, 특히 이 포스팅에서 진행한 ETF종목에 대해서 새로운 시야를 얻을 수 있었습니다.
GITHUB : https://github.com/siilver94/Stock-data-collection-analysis-and-visualization
GitHub - siilver94/Stock-data-collection-analysis-and-visualization
Contribute to siilver94/Stock-data-collection-analysis-and-visualization development by creating an account on GitHub.
github.com



