

Allen's 데이터 맛집
[머신러닝] 분류 : 자동차 시장 세분화 분류 예측 본문
Q. [마케팅] 자동차 시장 세분화
- 자동차 회사는 새로운 전략을 수립하기 위해 4개의 시장으로 세분화했습니다.
- 기존 고객 분류 자료를 바탕으로 신규 고객이 어떤 분류에 속할지 예측해 주세요!
- 예측할 값(y): "Segmentation" (1,2,3,4)
- 평가: Macro f1-score
- data: train.csv, test.csv
- 제출 형식:
ID,Segmentation 458989,1 458994,2 459000,3 459003,4
답안 제출 참고
- 아래 코드 예측변수와 수험번호를 개인별로 변경하여 활용
- pd.DataFrame({'ID': test.ID, 'Segmentation': pred}).to_csv('003000000.csv', index=False)
노트북 구분
- basic: 수치형 데이터만 활용 -> 학습 및 test데이터 예측
- intermediate: 범주형 데이터도 활용 -> 학습 및 test데이터 예측
- advanced: 학습 및 교차 검증(모델 평가) -> 하이퍼파라미터 튜닝 -> test데이터 예측
학습을 위한 채점
- 최종 파일을 "수험번호.csv"가 아닌 "submission.csv" 작성 후 오른쪽 메뉴 아래 "submit" 버튼 클릭 -> 리더보드에 점수 및 등수 확인 가능함
- pd.DataFrame({'ID': test.ID, 'Segmentation': pred}).to_csv('submission.csv', index=False)
데이터 불러오기
자동차 시장 세분화 분류를 위해 big-data-analytics-certification csv 파일을 불러옵니다.
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import pandas as pd
import numpy as np
X = pd.read_csv('/kaggle/input/big-data-analytics-certification-kr-2022/train.csv')
X_Submission = pd.read_csv('/kaggle/input/big-data-analytics-certification-kr-2022/test.csv')EDA
X = X.drop(columns = ['TravelInsurance'])
#print(X.shape, X_submission.shape)
# (1490, 9) (497, 9)
#print(X.info(), X_submission.info())
# 결측치X
object = ['Employment Type' ,'GraduateOrNot','FrequentFlyer','EverTravelledAbroad']
# print(X[object].nunique())
# print(X_submission[object].nunique())
# print(X['Employment Type'].unique())
# print(X_submission['Employment Type'].unique())
dfX = pd.concat([X, X_submission])
print(dfX.info(), dfX.shape)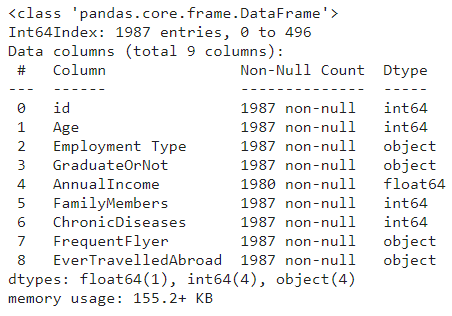
>>> (1987, 9)
전처리
dfX = pd.get_dummies(dfX)
#dfX.shape
#(1987, 14)
#dfX.info()
# 결측치 채우기
dfX['AnnualIncome'] = dfX['AnnualIncome'].fillna(dfX['AnnualIncome'].median())
dfX['AnnualIncome'].isna().sum()>>> 0
size = X.shape[0]
#print(size)
#1490
X1 = dfX.iloc[:size,:]
X_submission1 = dfX.iloc[size :,:]
print(X1.shape, X_submission1.shape)>>> (1490, 14) (497, 14)
모델 학습 및 예측
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_auc_score
xtrain, xtest, ytrain, ytest = train_test_split(X1, Y, test_size = 0.25,
stratify = Y, random_state = 7438)
print([x.shape for x in [xtrain, xtest, ytrain, ytest]])>>> (1117, 14), (373, 14), (1117,), (373,)
model1 = RandomForestClassifier(max_depth = 7,random_state = 7438).fit(xtrain, ytrain)
a = model1.score(xtrain, ytrain)
b = model1.score(xtest, ytest)
ypred = model1.predict_proba(xtest)[:,1]
c = roc_auc_score(ytest,ypred)
print(f' {x} {a:.4f} {b:.4f} {abs(a-b):.4f} {c:.4f}')>>> 3 0.7825 0.7989 0.0165 0.8305
>>> 4 0.7923 0.8097 0.0174 0.8371
>>> 5 0.8111 0.8231 0.0120 0.8469
>>> 6 0.8451 0.8338 0.0113 0.8489
>>> 7 0.8559 0.8525 0.0033 0.8563
>>> 8 0.8675 0.8445 0.0230 0.8499
X_submission1.id

model = RandomForestClassifier(max_depth = 7,random_state = 7438).fit(xtrain, ytrain)
ypred = model1.predict_proba(X_submission1)[:,1]
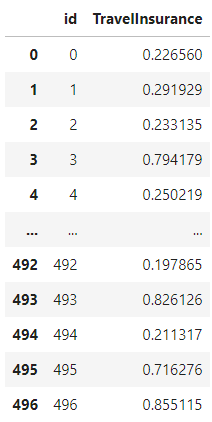
submission = pd.DataFrame({'id' : X_submission1.id, 'TravelInsurance' : ypred})
submission.to_csv('result.csv', index=False)
ddff = pd.read_csv('result.csv')
ddff
케글출처 : https://www.kaggle.com/competitions/big-data-analytics-certification-kr-2022
'Project/Kaggle 분석&기계학습' Related Articles
more



