Project/회전기계 고장유형 AI 데이터분석
[0] 회전기계 고장유형 AI 데이터 분석 프로젝트: 개요 및 목표
Allen93
2025. 5. 9. 13:20
이번 블로그에서는 KAMP의 「회전기계 고장유형 AI 데이터셋」을 기반으로 진행한 데이터 분석 프로젝트를 소개하려 합니다.
이 프로젝트는 회전기계의 진동 데이터를 활용하여 고장 유형을 예측하고, AI 기반의 상태 진단 모델을 구축하는 데 초점을 맞췄습니다. 제조업, 특히 회전 설비를 사용하는 현장에서 중요한 과제를 해결하기 위한 데이터를 다루었기에 실무에서 의미 있는 인사이트를 제공할 수 있는 프로젝트입니다.
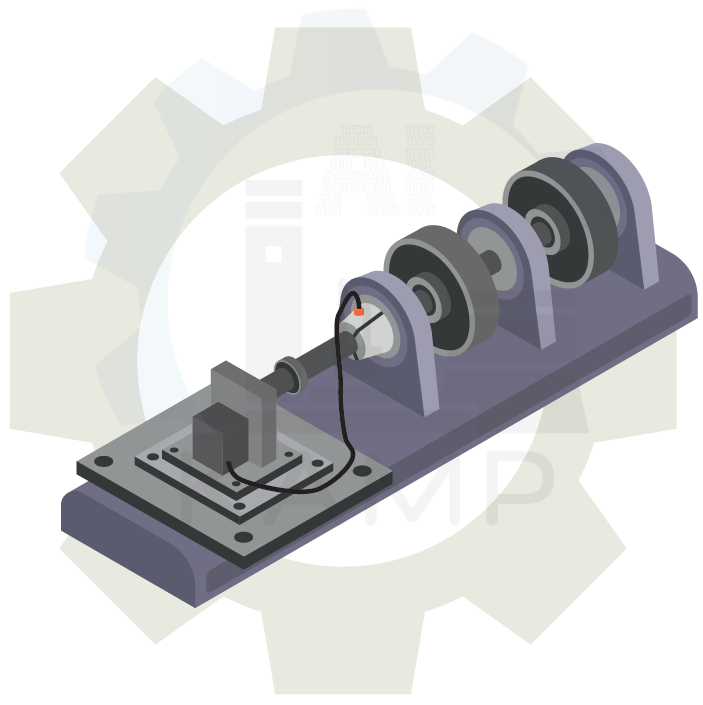
프로젝트 배경: 왜 회전기계 데이터를 분석하는가?
1. 회전기계의 중요성
회전기계는 터빈, 펌프, 압축기 등 여러 산업 공정의 핵심 설비로 사용됩니다.
만약 이들 기계가 고장 나면 공정이 중단되고, 이는 높은 유지보수 비용과 생산성 손실로 이어질 수 있습니다.
따라서 회전기계의 상태를 모니터링하고 고장을 예방하는 것은 매우 중요한 문제입니다.
2. 데이터의 부족과 한계
- 실제 산업 현장에서는 정상 데이터가 약 90% 이상을 차지하며, 고장 데이터는 드물게 발생합니다.
- 고장 데이터를 인위적으로 생성하려면 실제 기계에 고장을 가해야 하는데, 이는 매우 비효율적입니다.
이러한 한계를 극복하기 위해, 프로젝트에서는 Rotor Testbed라는 실험 장비를 사용해 다양한 고장 유형을 구현하고, 필요한 데이터를 수집했습니다.
프로젝트 목표: 고장을 예측하는 AI 모델 구축
1. 분석 목표
- 회전기계의 진동 데이터를 기반으로 정상 상태와 고장 유형을 분류하는 다중 분류 모델을 개발.
- 딥러닝 모델을 활용하여 데이터를 자동으로 분석하고, 비전문가도 활용할 수 있는 AI 분석 프레임워크를 구축.
2. 데이터 정의 및 특징
- 데이터셋 구조:
- Rotor Testbed의 4개의 센서로부터 수집된 시계열 데이터.
- 각 센서가 시간 순서에 따라 측정한 가속도 데이터를 포함.
- 데이터 수량: 약 140만 개의 행과 73MB의 용량으로 구성.
3. 기대효과
- 실제 산업 현장에서 발생하기 어려운 다양한 고장 데이터를 분석할 수 있도록 했습니다.
- 분석 결과는 발전소, 공장 등 다양한 산업 분야의 자동화 공정 개선에 활용될 수 있습니다.
데이터 분석 과정
프로젝트는 데이터를 수집하는 단계부터 AI 모델을 훈련시키는 단계까지 체계적으로 진행되었습니다.
각 과정은 가이드북의 표준 절차와 프로젝트 요구사항을 기반으로 설계되었습니다.
1. 데이터 수집 및 전처리
- 데이터 수집: Rotor Testbed를 사용해 다양한 고장 상황(질량 불균형, 지지 불량 등)을 재현하며 데이터를 얻음.
- 전처리:
- 선형보간법(Linear Interpolation)으로 샘플링 간격을 조정.
- 이동평균 필터로 노이즈 제거.
- Min-Max 정규화로 데이터 스케일을 조정하여 학습 효율성을 향상.
2. AI 모델 구축
- 적용 알고리즘:
- 심층신경망(DNN): 은닉층을 추가하여 학습 결과를 개선.
- 합성곱신경망(CNN): 시계열 데이터를 처리하며 특징 추출.
- 순환신경망(RNN): 시계열 데이터 학습에 특화.
마무리
이번 프로젝트는 회전기계 고장 데이터를 다각도로 분석하며, AI를 활용해 고장 유형을 진단할 수 있는 가능성을 확인했습니다.
다음 편에서는 데이터 전처리와 각 알고리즘별 결과를 분석한 내용을 자세히 다룰 예정입니다.
https://github.com/siilver94/AI-Analysis-of-Rotating-Machinery-Failure-Types
GitHub - siilver94/AI-Analysis-of-Rotating-Machinery-Failure-Types
Contribute to siilver94/AI-Analysis-of-Rotating-Machinery-Failure-Types development by creating an account on GitHub.
github.com
728x90